こちらは Symfony Advent Calendar 2021 の11日目の記事です。
昨日は @ttskch さんの [Symfony] Securityアノテーションを使って複雑な権限チェックを行う | blog.ttskch でした。
どーも @kalibora です。今回は 「エンジニアじゃなくたって現在時刻を自由自在に操ってテストがしたいよ〜〜(CV: マヂカルラブリー野田) with Symfony」 と題した記事です。
どういう話かといいますと、例えばお正月の1月1日からお正月キャンペーンのようなものをやるとして、画面が1/1の0時から切り替わるけど、それを前もってQAやPdMなどエンジニア以外の人がどうやって簡単にテストするか?みたいな話です。
前半は Symfony に関係ない一般的な話、後半はそれを Symfony でどう実装したか?という2段構えで書かせていただきます。
前段の話
現在時刻に依存するテスト
そもそも現在時刻に依存するテストというのは、テストではよくある話題です。
どのように現在時刻に依存するテストを書くかというのは超有名な 現在時刻が関わるユニットテストから、テスト容易性設計を学ぶ - t-wadaのブログ を参照していただくとして、
私はシンプルに
アプローチ1: シンプルに対象メソッドの引数に渡す
を使うことが多いですが、
Laravel 使いの方は Carbon を使っているでしょうから、Carbon::setTestNow() を使った
アプローチ2: 組み込みクラス/メソッド/関数に介入する
に近いアプローチを取っているでしょうし、
lcobucci/clock - Packagist のようなライブラリを使って
アプローチ7: 現在時刻へのアクセスを行うインターフェイスを抽出
のようなアプローチでもいいと思います。 とにかく、システム全体の設計として現在時刻を動的に変更してテストができる設計となっている事が重要です。
毎回現在時刻が欲しいのか、それとも処理が始まった時間が欲しいのか
現在時刻に関することでもう一つ気になるのは、毎回現在時刻が欲しいのか、それとも処理が始まった時間が欲しいのか?ということです。
例えば、1つの処理の中で2回現在時刻を元に何かを判断するクラス、メソッドを呼び出したときに、それぞれの呼び出しの間に重い処理があると、1秒以上現在時刻がズレます。
例としてこんな感じ。
- 2021/12/31 23:59:59 Foo::methodA() を呼び出す
- 重い処理で2秒経過
- 2022/01/01 00:00:01 Bar::methodB() を呼び出す
このときの Foo::methodA() と Bar::methodB() 内部で現在時刻を都度取得していると、日も年もまたいだ別の日時になります。 これが問題になるかどうかは要件次第ですが、1つの処理としては、処理の開始時刻が欲しいケースが多いのではないかと思います。
とくにWebアプリケーションの場合、処理の開始時刻はリクエスト時刻であり、PHP であれば
'REQUEST_TIME' リクエストの開始時のタイムスタンプ。
が使えます。
PHPのWebアプリケーションで現在時刻、もとい処理の開始時刻が欲しいのであれば、この値を使うといいのではないでしょうか。
エンジニア以外がどうやって現在時刻を操るか
エンジニアが行うユニットテストでは、単純にテストコード内で現在時刻を変えれば良いですが、QAやPdMのようなエンジニア以外が行うような実際のWebブラウザを通したテストではどのように時刻を操ればいいでしょうか?
私はHTTPヘッダーがその用途に適しているかと思います。 独自のHTTPヘッダーを定義し、その値として時刻を送信するという方法です。
クエリパラメーターを使ってもいいですが、これはアプリケーションの通常の用途で使う事が多いですし、URLに露出するのでコピペ時に邪魔になることもあります。
HTTPヘッダーであれば、URLにも露出しませんし、ブラウザの拡張機能(例: ModHeader - Chrome ウェブストア)で簡単に付与することも出来ます。
Symfony での実装方法
それではここから下記の条件での Symfony での実装方法の例を書いていきます。
- システム全体として、現在時刻を動的に変更してテストができる設計となっている
- 今回の私のケースだと
アプローチ1: シンプルに対象メソッドの引数に渡すをシステム全体を通して使っている
- 今回の私のケースだと
- 処理の開始時刻としてリクエスト時刻を使う
- HTTPヘッダーで任意の現在時刻(リクエスト時刻)に変更することを可能にする
リクエスト時刻を表すクラスの作成
最初にリクエスト時刻を表す RequestTime クラスを作成します。
<?php namespace App\Entity; // Value Object なので Entity じゃないけど、まぁどこか適当なところで final class RequestTime extends \DateTimeImmutable { public const REQUEST_ATTR_NAME = '_app_request_time'; private $debug = false; public function isDebug() : bool { return $this->debug; } public function setDebug(bool $debug) : self { $clone = clone $this; $clone->debug = $debug; return $clone; } }
DateTimeImmutable を継承しただけのクラスで、 REQUEST_ATTR_NAME 定数や isDebug メソッドなどありますが、それらは後で出てくるので一旦忘れてください。
リクエスト時刻を抽出するクラスの作成
先ほど作成した RequestTime を Request から抽出するクラスの Interface を定義します。
<?php namespace App\Service\RequestTime; use App\Entity\RequestTime; use Symfony\Component\HttpFoundation\Request; interface ExtractorInterface { public function extract(Request $request) : RequestTime; }
まずは通常の $_SERVER['REQUEST_TIME'] から RequestTime を抽出するクラスを作成します。
これは本番環境で使う想定です。
<?php namespace App\Service\RequestTime; use App\Entity\RequestTime; use Symfony\Component\HttpFoundation\Request; class Extractor implements ExtractorInterface { public function extract(Request $request) : RequestTime { $timestamp = $request->server->get('REQUEST_TIME'); $timezone = new \DateTimeZone(date_default_timezone_get()); return (new RequestTime("@{$timestamp}"))->setTimezone($timezone); } }
次に独自のHTTPヘッダーの値から任意の時刻の RequestTime を抽出するクラスを作成します。
これは dev や test 環境で使う想定です。
独自のHTTPヘッダー名はここでは X-Debug-Request-Time と定義しました。
<?php namespace App\Service\RequestTime; use App\Entity\RequestTime; use Symfony\Component\HttpFoundation\Request; class DebugExtractor extends Extractor { public const HEADER = 'X-Debug-Request-Time'; public function extract(Request $request) : RequestTime { if (($value = $request->headers->get(self::HEADER)) !== null) { $requestTime = $this->extractFromDebugHeader($value); if ($requestTime !== null) { return $requestTime; } } return parent::extract($request); } private function extractFromDebugHeader(string $value) : ?RequestTime { try { if (ctype_digit($value)) { $requestTime = new RequestTime("@{$value}"); } else { $requestTime = new RequestTime($value); } // 独自のHTTPヘッダーから取得した場合は debug を true にしておく return $requestTime->setDebug(true)->setTimezone(new \DateTimeZone(date_default_timezone_get())); } catch (\Exception $e) { // 入力が不正でもエラーにせず無視する } return null; } }
イベントリスナーにて抽出したリクエスト時刻を設定する
Symfony の イベントリスナー を使ってリクエストの attributes に、先程までに作った Extractor で抽出した RequestTime クラスを設定します。
Request に情報を追加するので、サブスクライブするイベントは kernel.request が良いかと思います。
<?php namespace App\EventSubscriber; use App\Entity\RequestTime; use App\Service\RequestTime\ExtractorInterface; use Symfony\Component\EventDispatcher\EventSubscriberInterface; use Symfony\Component\HttpFoundation\Response; use Symfony\Component\HttpKernel\Event\GetResponseEvent; use Symfony\Component\HttpKernel\KernelEvents; class RequestTimeSubscriber implements EventSubscriberInterface { private $extractor; public function __construct( ExtractorInterface $extractor ) { $this->extractor = $extractor; } public static function getSubscribedEvents() : array { return [ // Security Firewall よりは優先させる KernelEvents::REQUEST => ['onKernelRequest', 10], ]; } public function onKernelRequest(GetResponseEvent $event) : void { $request = $event->getRequest(); $requestTime = $this->extractor->extract($request); // リクエストの attributes に設定 $request->attributes->set(RequestTime::REQUEST_ATTR_NAME, $requestTime); } }
DIの設定をする
config/services.yaml では下記の様に、 ExtractorInterface として Extractor を使うように設定します。
App\Service\RequestTime\ExtractorInterface: class: App\Service\RequestTime\Extractor
config/services_dev.yaml と config/services_test.yaml では下記の様に ExtractorInterface として DebugExtractor を使うように設定します。
App\Service\RequestTime\ExtractorInterface: class: App\Service\RequestTime\DebugExtractor
これで dev, test 環境の時のみ、独自のHTTPヘッダーを用いて、リクエスト時刻を任意の時間に変える事が出来るようになります。(本番では $_SERVER['REQUEST_TIME'] からしか抽出しない)
あとはこれを各所で使うのみ
ここまでの実装で
$request->attributes->get(RequestTime::REQUEST_ATTR_NAME);
と書けばコントローラ等で任意のリクエスト時刻を取得できるので、現在時刻(リクエスト時刻)が必要なサービスなどのクラスに渡して使えばいいことになります。
さらに便利にする
Controller の引数にリクエスト時刻を渡せるようにする
Symfony では コントローラーのメソッドの引数に独自の引数を渡す事が出来る機能があります。 See: Extending Action Argument Resolving (Symfony Docs)
例えば、下記の様なクラスを作成すれば
<?php namespace App\ArgumentResolver; use App\Entity\RequestTime; use Symfony\Component\HttpFoundation\Request; use Symfony\Component\HttpKernel\Controller\ArgumentValueResolverInterface; use Symfony\Component\HttpKernel\ControllerMetadata\ArgumentMetadata; final class RequestTimeResolver implements ArgumentValueResolverInterface { public function supports(Request $request, ArgumentMetadata $argument) { if ($argument->getType() === RequestTime::class) { return true; } return false; } public function resolve(Request $request, ArgumentMetadata $argument) { yield $request->attributes->get(RequestTime::REQUEST_ATTR_NAME); } }
<?php namespace App\Controller; use App\Entity\RequestTime; class FooController { public function bar(RequestTime $now) // ここで RequestTime が受け取れる { } }
この様にコントローラーのメソッドの引数として受け取ることが出来るようになります。
Twig テンプレートでリクエスト時刻を使えるようにする
ついでに twig でも使えるようにしましょう。 これは簡単で、先に作成した RequestTimeSubscriber で Twig の Environment に設定するだけです。
<?php namespace App\EventSubscriber; // 省略 use Twig\Environment as TwigEnvironment; // 追加 class RequestTimeSubscriber implements EventSubscriberInterface { private $extractor; private $twig; // 追加 public function __construct( ExtractorInterface $extractor, TwigEnvironment $twig // 追加 ) { $this->extractor = $extractor; $this->twig = $twig; // 追加 } // 省略 public function onKernelRequest(GetResponseEvent $event) : void { // 省略 // ここで Twig の global に request_time として設定 $this->twig->addGlobal('request_time', $requestTime); } }
これで twig のテンプレートのどこでも request_time としてリクエスト時刻が取得できます。
デバッグバーにリクエスト時刻を出す
Symfony には dev 環境などでページ下部に表示されるデバッグバーがあります。
これがとても便利なので、このデバッグバーに認識されたリクエスト時刻を表示するようにします。 そして独自のHTTPヘッダで任意の時刻に偽装している場合は、分かりやすく赤い表示にしてみます。
参考にする公式ドキュメントは ここ です。
まず、データを収集するデータコレクタークラスの定義。
<?php namespace App\DataCollector; use App\Entity\RequestTime; use Symfony\Component\HttpFoundation\Request; use Symfony\Component\HttpFoundation\Response; use Symfony\Component\HttpKernel\DataCollector\DataCollector; class RequestTimeCollector extends DataCollector { public function collect(Request $request, Response $response, \Throwable $exception = null) : void { $this->data = [ 'request_time' => $request->attributes->get(RequestTime::REQUEST_ATTR_NAME), ]; } public function reset() : void { $this->data = []; } public function getName() : string { return 'app.request_time_collector'; } public function getRequestTime() : ?RequestTime { return $this->data['request_time'] ?? null; } }
それをDIで設定。
App\DataCollector\RequestTimeCollector: tags: - name: data_collector template: 'data_collector/template.html.twig' id: 'app.request_time_collector' priority: -1
そして templates/data_collector/template.html.twig にてテンプレートを書きます。
{% extends '@WebProfiler/Profiler/layout.html.twig' %}
{% block toolbar %}
{% if collector.requestTime %}
{% set icon %}
<svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="feather feather-clock"><circle cx="12" cy="12" r="10"></circle><polyline points="12 6 12 12 16 14"></polyline></svg>
{% set status_color = collector.requestTime.isDebug ? 'red' : '' %}
<span class="sf-toolbar-value">{{ collector.requestTime|date('Y/m/d H:i:s') }}</span>
{% endset %}
{% set text %}
<div class="sf-toolbar-info-piece">
<b>リクエスト時刻</b>
<span>{{ collector.requestTime|date('Y/m/d H:i:s') }}</span>
</div>
<div class="sf-toolbar-info-piece">
<b>デバッグモード</b>
<span class="sf-toolbar-status sf-toolbar-status-{{ collector.requestTime.isDebug ? 'red' : 'green' }}">{{ collector.requestTime.isDebug ? 'Yes' : 'No' }}</span>
</div>
{% endset %}
{{ include('@WebProfiler/Profiler/toolbar_item.html.twig', { link: false, status: status_color }) }}
{% endif %}
{% endblock %}
こんな感じで書くと、下記のようなデバッグツールバーが生成できます。
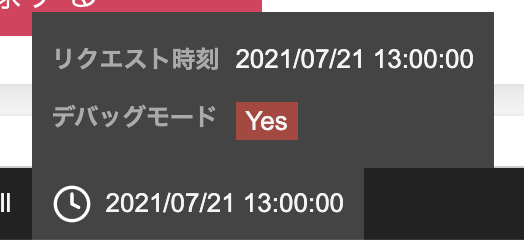
まとめ
これで、QAやPdMなどのエンジニア以外の人も、ブラウザの拡張機能を使って独自のHTTPヘッダーを設定し、任意の時刻のテストが出来るようになりました。
キャンペーン系のテストなどは捗りますし、Symfony の機能を上手く用いて無理なく便利に実装出来たのではないかと思います。
Symfony Advent Calendar 2021 明日は @77web さんです。お楽しみに!